clinicadl random-search - Launch and analyse random search results¶
clinicadl random-search generate- Train random models sampled from a defined hyperparameter space¶
This functionality trains a random model with hyperparameters sampled from a predefined space.
The hyperparameter space is defined in a random_search.json file that must be manually filled
by the user. Some of its variables are mandatory.
This file contains the fixed values or intervals / sets to sample from. The sampling function are the following:
choicesamples one element from a list,uniformdraws samples from a uniform distribution over the interval [min,max],exponentdrawsxfrom a uniform distribution over the interval [min,max] and return 10-x.randintreturns an integer in [min,max].
The values of some variables are also fixed, meaning that they cannot be sampled and
that they should be given a unique value.
The values of the variables that can be set in random_search.json correspond to
the options of the train function except for the
Computational resources, Cross-validation arguments and output_directory
that are defined with the commandline arguments.
Some variables were also added to sample the architecture of the network.
Prerequisites¶
You need to execute the clinicadl tsvtool getlabels
and clinicadl tsvtool {split|kfold} commands
prior to running this task to have the correct TSV file organization.
Moreover, there should be a CAPS, obtained running the t1-linear pipeline of ClinicaDL.
Running the task¶
This task can be run with the following command line:
clinicadl random-search generate <launch_directory> <name>
launch_directory(str) is the parent directory of output folder containing the filerandom_search.json.name(str) is the name of the output folder containing the experiment.
Content of random_search.json¶
random_search.json must be present in launch_dir before running the command.
An example of this file can be found in
clinicadl/clinicadl/tools/deep_learning/models.
Mandatory variables:
mode(str) is the type of input used. Must be chosen betweenimage,patch,roiandslice. Sampling function:choice.network_type(str) is the type of network used. The options depend on the type of input used, but at most it can be chosen betweenautoencoder,cnnandmulticnn. Sampling function:choice.caps_dir(str) is the input folder containing the neuroimaging data in a CAPS hierarchy. Sampling function:fixed.preprocessing(str) corresponds to the preprocessing pipeline whose outputs will be used for training. Sampling function:choice.tsv_path(str) is the input folder of a TSV file tree generated byclinicadl tsvtool {split|kfold}. Sampling function:fixed.diagnoses(list of str) is the list of the labels that will be used for training. Sampling function:fixed.epochs(int) is the maximum number of epochs. Sampling function:fixed.n_convblocks(int) is the number of convolutional blocks in CNN. Sampling function:randint.first_conv_width(int) is the number of kernels in the first convolutional layer. Sampling function:choice.n_fcblocks(int) is the number of fully-connected layers at the end of the CNN. Sampling function:randint.
Optional variables:
- Architecture hyperparameters
channels_limit(int) is the maximum number of output channels that can be found in the CNN. Sampling function:fixed. Default:512.d_reduction(str) is the type of dimension reduction applied to the feature maps. Must include onlyMaxPoolingorstride. In this case the dimension is reduced by having a stride of 2 in one convolutional layer per convolutional block. Sampling function:choice. Default:MaxPooling.n_conv(int) is the number of convolutional layers in a convolutional block. It is sampled independently for each convolutional block. Sampling function:randint. Default:1.network_normalization(str) is the type of normalization performed after convolutions. Must include onlyBatchNorm,InstanceNormorNone. Sampling function:choice. Default:BatchNorm.
- Computational resources
--use_cpu(bool) forces to use CPU. Default behaviour is to try to use a GPU and to raise an error if it is not found.--nproc(int) is the number of workers used by the DataLoader. Default value:2.--batch_size(int) is the size of the batch used in the DataLoader. Default value:2.--evaluation_steps(int) gives the number of iterations to perform an evaluation internal to an epoch. Default will only perform an evaluation at the end of each epoch.
- Data management
baseline(bool) allows to only load_baseline.tsvfiles when set toTrue. Sampling function:choice. Default:False.data_augmentation(list of str) is the list of data augmentation transforms applied to the training data. Must be chosen in [None,Noise,Erasing,CropPad,Smoothing]. Sampling function:fixed. Default:False.unnormalize(bool) is a flag to disable min-max normalization that is performed by default. Sampling function:choice. Default:False.sampler(str) is the sampler used on the training set. It must be chosen in [random,weighted]. Sampling function:choice. Default:random.
- Cross-validation arguments
--n_splits(int) is a number of splits k to load in the case of a k-fold cross-validation. Default will load a single-split.--split(list of int) is a subset of folds that will be used for training. By default all splits available are used.
- Optimization parameters
learning_rate(float) is the learning rate used to perform weight update. Sampling function:exponent. Default:4(leading to a value of1e-4).wd_bool(bool) usesweight_decayifTrue, else weight decay of Adam optimizer is set to 0. Sampling function:choice. Default:True.weight_decay(float) is the weight decay used by the Adam optimizer. Sampling function:exponent, conditioned bywd_bool. Default:4(leading to a value of1e-4).dropout(float) is the rate of dropout applied in dropout layers. Sampling function:uniform. Default:0.0.patience(int) is the number of epochs for early stopping patience. Sampling function:fixed. Default:0.tolerance(float) is the value used for early stopping tolerance. Sampling function:fixed. Default:0.0. "accumulation_steps": 1
- Transfer learning
--transfer_learning_path(str) is the path to a result folder (output ofclinicadl train). The best model of this folder will be used to initialize the network as explained in the implementation details. If nothing is given the initialization will be random.--transfer_learning_selection(str) corresponds to the metric according to which the best model oftransfer_learning_pathwill be loaded. This argument will only be taken into account if the source network is a CNN. Choices arebest_lossandbest_balanced_accuracy. Default:best_balanced_accuracy.
Mode-dependent variables:
- patch
- patch_size (int) size of the patches in voxels.
Sampling function: randint. Default: 50.
- selection_threshold (float) threshold on the balanced accuracies to compute the
image-level performance.
Patches are selected if their balanced accuracy is greater than the threshold.
Sampling function: uniform. Default will perform no selection.
- stride_size (int) length between the centers of successive patches in voxels.
Sampling function: randint. Default: 50.
- use_extracted_patches (bool) if set to True, the outputs of clinicadl extract are used.
Otherwise, the whole 3D MR volumes are loaded and patches are extracted on-the-fly.
- roi
- selection_threshold (float) threshold on the balanced accuracies to compute the
image-level performance.
Patches are selected if their balanced accuracy is greater than the threshold.
Sampling function: uniform. Default will perform no selection.
- slice
- discarded_slices (list of int) number of slices discarded from respectively the beginning and the end of the MRI volume.
If only one argument is given, it will be used for both sides.
Sampling function: randint. Default: 20.
- selection_threshold (float) threshold on the balanced accuracies to compute the
image-level performance.
Slices are selected if their balanced accuracy is greater than the threshold.
Sampling function: uniform. Default corresponds to no selection.
- slice_direction (int) axis along which the MR volume is sliced.
Sampling function: choice. Default: 0.
- 0 corresponds to the sagittal plane,
- 1 corresponds to the coronal plane,
- 2 corresponds to the axial plane.
- --use_extracted_slices (bool) if set to True, the outputs of clinicadl extract are used.
Otherwise, the whole 3D MR volumes are loaded and slices are extracted on-the-fly.
Sampling function: fixed. Default: False.
Sampling different modes
The mode-dependent variables are used only if the corresponding mode is sampled.
Outputs¶
Results are stored in the results folder given by launch_dir, according to
the following file system:
<launch_dir>
├── random_search.json
└── <name>
Example of setting¶
In the following we give an example of a random_search.json file and
two possible sets of options that can be sampled from it.
random_search.json¶
{"mode": ["patch", "image"],
"network_type": "cnn",
"caps_dir": "/path/to/caps",
"preprocessing": "t1-linear",
"tsv_path": "/path/to/tsv",
"diagnoses": ["AD", "CN"],
"epochs": 100,
"learning_rate": [2, 5],
"wd_bool": [true, false],
"weight_decay": [2, 4],
"dropout": [0, 0.9],
"n_convblocks": [2, 6],
"first_conv_width": [4, 8, 16, 32],
"channels_limit": 64,
"d_reduction": ["MaxPooling", "stride"],
"network_normalization": [null, "BatchNorm"]
"n_conv": [1, 2],
"n_fcblocks": [1, 3]}
Options #1¶
{"mode": "image",
"network_type": "cnn",
"caps_dir": "/path/to/caps",
"preprocessing": "t1-linear",
"tsv_path": "/path/to/tsv",
"diagnoses": ["AD", "CN"],
"baseline": False,
"unnormalize": False,
"data_augmentation": False,
"sampler": "random",
"epochs": 100,
"learning_rate": 5.64341e-4,
"wd_bool": True,
"weight_decay": 4.87963e-3,
"patience": 20,
"tolerance": 0,
"accumulation_steps": 1,
"evaluation_steps": 0,
"network_normalization": None
"convolutions":
{"conv0": {"in_channels": 1, "out_channels": 8, "n_conv": 2, "d_reduction": "MaxPooling"},
"conv1": {"in_channels": 8, "out_channels": 16, "n_conv": 3, "d_reduction": "MaxPooling"},
"conv2": {"in_channels": 16, "out_channels": 32, "n_conv": 2, "d_reduction": "MaxPooling"},
"conv3": {"in_channels": 32, "out_channels": 64, "n_conv": 1, "d_reduction": "MaxPooling"},
"conv4": {"in_channels": 64, "out_channels": 64, "n_conv": 1, "d_reduction": "MaxPooling"},
"fc":
{"FC0": {"in_features": 16128, "out_features": 180},
"FC1": {"in_features": 180, "out_features": 2}}, "dropout": 0.06792280327917641}
}
In this case weight decay is applied, and the values for the hyperparameters of the architecture are the following:
"n_convblocks": 5,
"first_conv_width": 8,
"channels_limit": 64,
"d_reduction": "MaxPooling",
"n_fcblocks": 2
n_conv is sampled independently for each convolutional block, leading to a different
number of layers for each convolutional block, described in the conv dictionnary.
The number of features in fully-connected layers is computed such as the ratio between
each layer is equal (here 16128 / 180 ≈ 180 / 2).
The scheme of the corresponding architecture is the following:
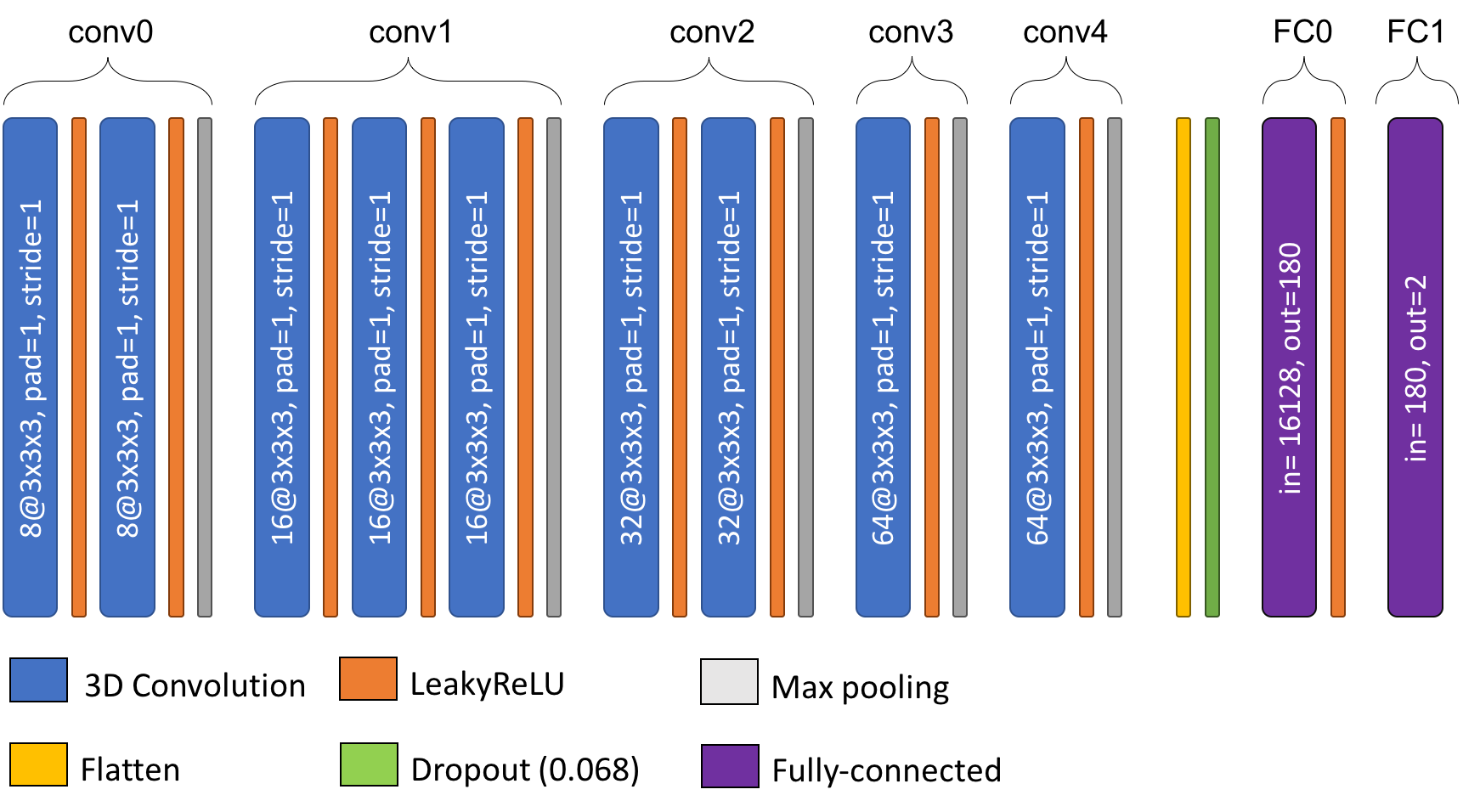
Options #2¶
{"mode": "patch",
"network_type": "cnn",
"caps_dir": "/path/to/caps",
"preprocessing": "t1-linear",
"tsv_path": "/path/to/tsv",
"diagnoses": ["AD", "CN"],
"baseline": False,
"unnormalize": False,
"data_augmentation": False,
"sampler": "random",
"epochs": 100,
"learning_rate": 7.09740e-3,
"wd_bool": False,
"weight_decay": 4.09832e-4,
"patience": 20,
"tolerance": 0,
"accumulation_steps": 1,
"evaluation_steps": 0,
"network_normalization": None
"convolutions":
{"conv0": {"in_channels": 1, "out_channels": 16, "n_conv": 2, "d_reduction": "stride"},
"conv1": {"in_channels": 16, "out_channels": 32, "n_conv": 3, "d_reduction": "stride"},
"conv2": {"in_channels": 32, "out_channels": 64, "n_conv": 2, "d_reduction": "stride"}}
"fc":
{"FC0": {"in_features": 21952, "out_features": 2}}, "dropout": 0.5783296483092104}
}
In this case weight decay is not applied, and the values for the hyperparameters of the architecture are the following:
"n_convblocks": 3,
"first_conv_width": 16,
"channels_limit": 64,
"d_reduction": "stride",
"n_fcblocks": 1
n_conv is sampled independently for each convolutional block, leading to a different
number of layers for each convolutional block, described in the conv dictionnary.
The scheme of the corresponding architecture is the following:

clinicadl random-search analysis - Find best performing jobs¶
This tool allows to parse all the jobs trained with ClinicaDL and produces a TSV files that indicates how many jobs have a validation balanced accuracy higher than a threshold (from 0.50 to 0.95).
Prerequisites¶
A random search must have run in launch_directory, so
clinicadl random-search generate <launch_directory> must have been executed at least one time.
Running the task¶
This task can be run with the following command line:
clinicadl random-search analysis <launch_directory>
launch_directory (str) is the parent directory of output folder containing the file random_search.json.
Outputs¶
Two TSV files are produced in launch_directory:
- analysis_balanced_accuracy.tsv which gives the results of the best models according to validation balanced accuracy,
- analysis_balanced_accuracy.tsv which gives the results of the best models according to validation loss.
The content of these TSV files is as follows:
run >0.5 >0.55 ... >0.85 >0.9 >0.95 folds
job-0 1 1 1 0 0 0 4
job-1 1 1 1 0 0 0 3
...
job-10 1 1 1 1 0 0 3
total 9 8 8 2 1 0 32
where:
- the column run indicates if the job has run are not (it can crash at the beginning because the
architecture chosen is too large for the GPU).
- the columns >XX indicates if the job has a validation balanced accuracy higher than XX.
- the columns folds indicates how many folds were found for this job,
- the last row total is the sum of all the previous rows.